Recentemente ho riscontrato uno strano comportamento dell’optimizer Oracle su un SQL statement di MERGE.
Il problema
I tempi medi di esecuzione per questo statement SQL erano di circa 5-8 minuti, lo statement SQL era composto da una “semplice” MERGE tra una tabella partizionata su circa 1,5 miliardi di righe ed una tabella vuota(??). L’elapsed time riscontrato mi ha sorpreso.
Ho quindi eseguito un test case creando due tabelle che chiamerò T_BIG con 510M di righe e T_SMALL con 0 righe.
Rispetto al caso reale la mia t_big table ha meno della metà delle righe e un numero di colonne decisamente inferiore (nel caso reale la tabella aveva circa 100 colonne) ma poco importa, il problema si ripete anche con un numero di righe e di colonne decisamente inferiore.
Eseguo la MERGE con un DOP di 4 abilitando la modalità parallel DML su un db 12c versione 12.2:
SQL> select banner from v$version;
BANNER
---------------------------------------------------------------------------
Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production
PL/SQL Release 12.2.0.1.0 - Production
CORE 12.2.0.1.0 Production
TNS for Linux: Version 12.2.0.1.0 - Production
NLSRTL Version 12.2.0.1.0 - Production
SQL> MERGE /*+ PARALLEL(4) ENABLE_PARALLEL_DML */ INTO t_big b
2 USING t_small a
3 ON (a.id=b.id)
4 WHEN MATCHED THEN
5 UPDATE /*+ PARALLEL(4) */
6 SET b.d2=TO_DATE('19-MAR-2020 00:00:00', 'dd-mon-yyyy hh24:mi:ss')-(1/24/60/60),
7 b.d3= TO_DATE('19-MAR-2020 00:00:00', 'dd-mon-yyyy hh24:mi:ss')
8 WHEN NOT MATCHED THEN
9 INSERT (ID, d1, d2, d3, v)
10 VALUES (a.id, a.d, a.d, a.d, a.v);
0 di righe unite.
Passati: 00:00:14.31
perchè 14 secondi se la tabella t_small è vuota? (nel caso reale come già detto i tempi erano ben più elevati).
Se eseguo lo stesso statement SQL in sequenziale ho una prima sorpresa:
SQL> MERGE /*+ NO_PARALLEL */ INTO t_big b
2 USING t_small a
3 ON (a.id=b.id)
4 WHEN MATCHED THEN
5 UPDATE
6 SET b.d2=TO_DATE('19-MAR-2020 00:00:00', 'dd-mon-yyyy hh24:mi:ss')-(1/24/60/60),
7 b.d3= TO_DATE('19-MAR-2020 00:00:00', 'dd-mon-yyyy hh24:mi:ss')
8 WHEN NOT MATCHED THEN
9 INSERT (ID, d1, d2, d3, v)
10 VALUES (a.id, a.d, a.d, a.d, a.v);
0 di righe unite.
Passati: 00:00:00.02
elapsed time praticamente azzerato, perchè questa differenza?
Analisi utilizzando SQL MONITOR
SQL monitor indica che l’elapsed time dello statement SQL eseguito in modalità PARALLEL viene speso/perso in I/O:
Global Information
------------------------------
Status : DONE
Instance ID : 1
Session : SETTEMBRINO (264:53010)
SQL ID : 1avy88pz9nzz4
SQL Execution ID : 16777217
Execution Started : 05/08/2020 01:53:22
First Refresh Time : 05/08/2020 01:53:22
Last Refresh Time : 05/08/2020 01:53:36
Duration : 14s
Module/Action : SQL*Plus/-
Service : ora12b1.icteam.local
Program : sqlplus.exe
Global Stats
========================================================
| Elapsed | Cpu | IO | Buffer | Read | Read |
| Time(s) | Time(s) | Waits(s) | Gets | Reqs | Bytes |
========================================================
| 57 | 55 | 1.91 | 893K | 7073 | 7GB |
========================================================
viene letta una tabella di 510M di righe con circa 900k buffer per eseguire una MERGE contro una tabella di 0 righe, quindi tutto I/O inutile.
Il piano di esecuzione conferma che quasi tutto il tempo (14 sec) viene impiegato leggendo la tabella t_big
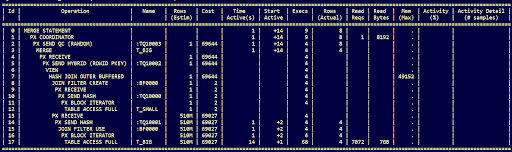
*Nota: prestare attenzione alla riga 6 del piano di esecuzione, VIEW potrebbe stare ad indicare un blocco di query ottimizzato e trasformato.
In modalità sequenziale lo statement SQL dura 264 microsecondi, l’ I/O scompare completamente:
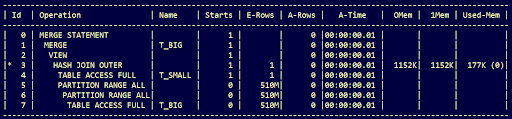
Tracing SQL statement
Guardando il file di trace 10053 ho individuato la trasformazione dello statement eseguita dal query optimizer:
CVM: Merging SPJ view SEL$2 (#0) into SEL$1 (#0)
Registered qb: SEL$F5BB74E1 0xb06cf68 (VIEW MERGE SEL$1; SEL$2; SEL$1)
La trasformazione applicata è del tipo CVM (Complex View Merging), Oracle genera quindi un nuovo blocco (qb sta ad indicare un query block) di nome SEL$F5BB74E1 frutto del merge tra il blocco SEL$2 (tabella T_BIG) e SEL$1 (tabella T_SMALL):
Il nuovo blocco creato, SEL$F5BB74E1, corrisponde al seguente statement SQL di select:
SQL> SELECT 0
2 FROM (SELECT /*+ NO_MERGE */ "B".ROWID,"B"."ID" "ID","B"."D1" "D1","B"."D2" "D2","B"."D3" "D3","B"."V" "V","A"."ID" "ID","A"."D" "D","A"."V" "V"
3 FROM "SETTEMBRINO"."T_SMALL" "A","SETTEMBRINO"."T_BIG" "B"
4 WHERE "A"."ID"="B"."ID"(+)
5 ) "from$_subquery$_006","SETTEMBRINO"."T_SMALL" "A", "SETTEMBRINO"."T_BIG" "B" ;
Nessuna riga selezionata
Passati: 00:00:14.80
L’elapsed time di quest’ultima esecuzione assomiglia molto ai 14 secondi impiegati dallo statement SQL di MERGE. Quindi il tempo speso dallo statement di MERGE viene speso/perso da questo blocco per recuperare le eventuali righe utili.
Come posso risolvere il problema?
La trasformazione interna attuata dal query optimizer non è visibile guardando il solo piano di esecuzione della MERGE. Ma adesso conosco che è stata eseguita una trasformazione CVM. Potrei pensare di inibire la trasformazione utilizzando l’hint NO_QUERY_TRANSFORMATION ad esempio:
SQL> MERGE /*+ parallel(4) enable_parallel_dml NO_QUERY_TRANSFORMATION */ INTO t_big b
2 USING t_small a
3 ON (a.id=b.id)
4 WHEN MATCHED THEN
5 UPDATE /*+ PARALLEL(4) */ SET b.d2=TO_DATE('19-MAR-2020 00:00:00', 'dd-mon-yyyy hh24:mi:ss')-(1/24/60/60),
6 b.d3= TO_DATE('19-MAR-2020 00:00:00', 'dd-mon-yyyy hh24:mi:ss')
7 WHEN NOT MATCHED THEN
8 INSERT
9 (ID, d1, d2, d3, v)
10 VALUES
11 (a.id, a.d, a.d, a.d, a.v);
0 di righe unite.
Passati: 00:00:00.05
Ok, raggiungo il mio obiettivo (tempo di esecuzione dello statement di MERGE praticamente azzerato) ma ho anche disabilitato tutte le funzionalità di trasformazione del query optimizer, posso fare qualcosa di meglio?
Diamo un’occhiata alla sezione Outline del piano di esecuzione:
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY(format=>'basic +alias +outline'));
----------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------
| 0 | MERGE STATEMENT | |
| 1 | PX COORDINATOR | |
| 2 | PX SEND QC (RANDOM) | :TQ10003 |
| 3 | MERGE | T_BIG |
| 4 | PX RECEIVE | |
| 5 | PX SEND HYBRID (ROWID PKEY)| :TQ10002 |
| 6 | VIEW | |
| 7 | HASH JOIN OUTER BUFFERED | |
| 8 | JOIN FILTER CREATE | :BF0000 |
| 9 | PX RECEIVE | |
| 10 | PX SEND HASH | :TQ10000 |
| 11 | PX BLOCK ITERATOR | |
| 12 | TABLE ACCESS FULL | T_SMALL |
| 13 | PX RECEIVE | |
| 14 | PX SEND HASH | :TQ10001 |
| 15 | JOIN FILTER USE | :BF0000 |
| 16 | PX BLOCK ITERATOR | |
| 17 | TABLE ACCESS FULL | T_BIG |
----------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - MRG$1
7 - SEL$F5BB74E1
12 - SEL$F5BB74E1 / A@SEL$1
17 - SEL$F5BB74E1 / B@SEL$2
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
PX_JOIN_FILTER(@"SEL$F5BB74E1" "B"@"SEL$2")
PQ_DISTRIBUTE(@"SEL$F5BB74E1" "B"@"SEL$2" HASH HASH)
USE_HASH(@"SEL$F5BB74E1" "B"@"SEL$2")
LEADING(@"SEL$F5BB74E1" "A"@"SEL$1" "B"@"SEL$2")
FULL(@"SEL$F5BB74E1" "B"@"SEL$2")
FULL(@"SEL$F5BB74E1" "A"@"SEL$1")
USE_MERGE_CARTESIAN(@"MRG$1" "B"@"MRG$1")
USE_MERGE_CARTESIAN(@"MRG$1" "A"@"MRG$1")
LEADING(@"MRG$1" "from$_subquery$_006"@"MRG$1" "A"@"MRG$1" "B"@"MRG$1")
FULL(@"MRG$1" "B"@"MRG$1")
FULL(@"MRG$1" "A"@"MRG$1")
NO_ACCESS(@"MRG$1" "from$_subquery$_006"@"MRG$1")
OUTLINE(@"SEL$2")
OUTLINE(@"SEL$1")
OUTLINE_LEAF(@"MRG$1")
MERGE(@"SEL$2" >"SEL$1")
OUTLINE_LEAF(@"SEL$F5BB74E1")
ALL_ROWS
OPT_PARAM('optimizer_dynamic_sampling' 5)
OPT_PARAM('_optimizer_gather_stats_on_load' 'false')
DB_VERSION('12.2.0.1')
OPTIMIZER_FEATURES_ENABLE('12.2.0.1')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/
Tra le principali evidenze che riscontro, oltre a ritrovare la subquery utilizzata nella trasformazione ("from$_subquery$_006") ed il query block utilizzato e che ho individuato nel file di trace 10053 (SEL$F5BB74E1) ho notato anche l’hint MERGE(@"SEL$2" >"SEL$1") utilizzato (dalla versione 12.2) per fare il MERGE di due query blocks.
Inserisco quindi al mio statement di MERGE un hint di NO_MERGE sul query block SEL$2 per evitare la trasformazione fatta dal query optimizer:
SQL> MERGE /*+ PARALLEL(4) ENABLE_PARALLEL_DML NO_MERGE(@SEL$2) */ INTO t_big b
2 USING t_small a
3 ON (a.id=b.id)
4 WHEN MATCHED THEN
5 UPDATE /*+ PARALLEL(4) */ SET b.d2=TO_DATE('19-MAR-2020 00:00:00', 'dd-mon-yyyy hh24:mi:ss')-(1/24/60/60),
6 b.d3= TO_DATE('19-MAR-2020 00:00:00', 'dd-mon-yyyy hh24:mi:ss')
7 WHEN NOT MATCHED THEN
8 INSERT
9 (ID, d1, d2, d3, v)
10 VALUES
11 (a.id, a.d, a.d, a.d, a.v);
0 di righe unite.
Passati: 00:00:00.06
Bingo!!! il mio statement di MERGE diventa veloce rispondendo in “tempo zero”, il piano di esecuzione è quindi cambiato, ritrovo un Nested Loop al posto dell’hash join e l’accesso sulla big table avviene mediante utilizzo di Lateral View (inline view correlata).
-----------------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------------
| 0 | MERGE STATEMENT | |
| 1 | PX COORDINATOR | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 |
| 3 | MERGE | T_BIG |
| 4 | PX RECEIVE | |
| 5 | PX SEND HYBRID (ROWID PKEY)| :TQ10000 |
| 6 | VIEW | |
| 7 | NESTED LOOPS OUTER | |
| 8 | PX BLOCK ITERATOR | |
| 9 | TABLE ACCESS FULL | T_SMALL |
| 10 | PARTITION RANGE ALL | |
| 11 | PARTITION RANGE ALL | |
| 12 | VIEW | VW_LAT_A18161FF |
| 13 | TABLE ACCESS FULL | T_BIG |
-----------------------------------------------------------
Conclusioni
Non riesco a trovare una spiegazione a questo strano comportamento guardando il piano di esecuzione, noto una “normale” Hash Join al quale viene applicato un normale Bloom Filter. In teoria l’optimizer Oracle si accorge che la build table (t_small) ha una cardinality di 0 righe, quindi lo statement dovrebbe evitare la lettura della probe table (t_big). Anche la bufferizzazione delle righe utili nell’operazione di Join indicata nel piano di esecuzione (HASH JOIN OUTER BUFFERED) non può tecnicamente avvenire in quanto la (hash) build table non verrà mai costruita in memoria in quanto vuota. A questo punto devo ritenere che si tratti di un bug. Questo strano comportamento è stato rilevato non solo in versione 12c ma l’ho riscontrato anche nelle versioni 18.3 e 19.5.
Oracle Specialist at Performance Team @ ICTeam Spa