Da sempre, uno dei più importanti problemi da affrontare nel mondo della Data Science è l’arricchimento del dato per incrementarne la qualità (Data Quality): per i data scientists tale tematica diventa difficile, soprattutto, in quanto la configurazione di una procedura di arricchimento richiede, la maggior parte delle volte, troppo tempo.
Nelle infrastrutture Big Data tali considerazioni diventano di ancor maggiore rilevanza: con una procedura di arricchimento del dato, anche la tematica dello storage del dato deve essere presa in considerazione, penalizzando ulteriormente una strategia di Data Quality "manuale".
In tali contesti è essenziale avere uno strumento di data integration per ridurre il gap di tempo tra data preparation (tra cui l’arricchimento del dato) e l’effettiva analisi, in tal modo i data scientist possono delegare grossa parte della prima fase di lavoro allo strumento, senza doversi preoccupare di come la procedura di preparazione del dato è effettivamente implementata, e dove è eseguita.
Per questa ragione ICTeam ha scelto Data Science Studio (DSS) di Dataiku come strumento di data integration e data science, guadagnandosi la possibilità di realizzare un’ampia gamma di progetti in ambito "Big" Data Science, sfruttando appieno le potenzialità di clusters HDFS/SPARK, senza doversi occupare, di volta in volta, sull’implementazione effettiva di ogni singolo step del flusso di data mining.
DSS fornisce un’ampia varietà di componenti (processors) per filtrare e arricchire il dato, preservando la "data locality" e mantenendo trasparenza d’esecuzione ai Data Scientist, consentendogli di concentrarsi solamente sull’analisi del dato vera e propria (Figura 1). Ad ogni modo, lo scopo di tale presentazione è riguardante l’arricchimento del dato, ed è in tale contesto che DSS fornisce un vero rinforzo all’analisi: ogni componente di "enrichment" è fornito nello stesso ambiente di sviluppo degli altri "processors", e può combinare diverse fonti dati senza alcun problema di integrazione, lasciando il flusso dati perfettamente coerente. Ogni componente di DSS è realizzato attraverso codice Python e reso accessibile all’utente, il quale lo visualizza come un semplice "processor" DSS, senza obbligarlo a scrivere una singola linea di codice. Proprio per tale ragione Dataiku ha aperto la propria piattaforma agli sviluppatori, fornendo un semplice insieme di API che rendono estremamente semplice la trasformazione di codice di arricchimento dati Python in plugin DSS. ICTeam crede fermamente che tale approccio sia vincente, soprattutto nell’emergente settore della Big Data Science, dove la possibilità di arricchire, pulire e trasformare una grossa quantità di dati in maniera trasparente e attraverso un unico e coerente ambiente di sviluppo è vitale al fine di realizzare con successo progetti di "advanced analytics". Questa è la principale ragione che ci ha spinto a incominciare a sviluppare procedure Python/PySpark di "Data Quality", trasformate poi con facilità in plugin DSS, che consentono di fornire un ambiente di sviluppo DSS arricchito, in grado di rispondere perfettamente alle esigenze del cliente.
Tali sforzi, tra le altre cose, hanno portato alla realizzazione della plugin MUSIXMATCH (http://www.dataiku.com/dss/plugins/info/musixmatch.html) basata sul popolare catalogo di testi musicale: tale plugin di "data enrichment" prende come input una lista di artisti musicali e, per ognuno di loro, vengono recuperati i metadati per ogni traccia che hanno prodotto, congiuntamente con i relativi testi forniti da MUSIXMATCH. Tale procedura porta alla generazione di un nuovo dataset, composto da un ampio insieme di dati per una data lista di artisti, senza fornire alla piattaforma niente se non i normi degli artisti e una Api Key di MUSIXMATCH. E’ facile comprendere come, sfruttando questa nuova generazione di strumenti, sia facile generare una significativa quantità di dati strutturati, senza la richiesta di un particolare sforzo implementativo da parte dei data scientists.
Ciò che è stato presentato, è solamente un esempio di un nuovo approccio nel mondo Data Science, dove uno dei principali obiettivi è ridurre l’ampio margine di tempo speso tra la fase di preparazione del dato e effettivo data mining (il celebre partizionamento 80-20), lasciando ai data scientist il tempo di aumentare i propri sforzi sulle fasi di definizione dei modelli predittivi (Machine Learning). Come ICTeam siamo una delle prime aziende italiane a investire in tale direzione, testimoniato dal fatto di essere il primo partner Dataiku italiano certificato, e il primo, in assoluto, sviluppatore di terze parti ad aver pubblicato una plugin DSS.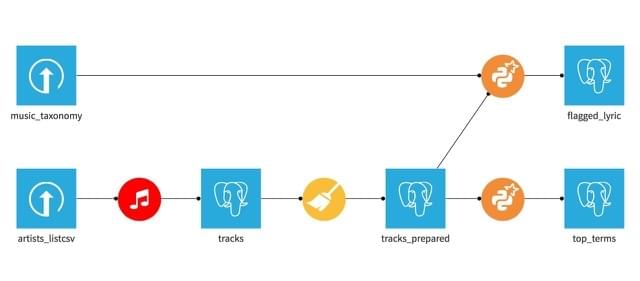
Esempio di un flusso dati DSS, si osservi che ogni dataset è trattato sempre allo stesso modo, indipendentemente dall’operazione eseguita su di esso o dalla fonte dati di appartenenza
Data Scientist @ ICTeam S.p.A